Vorstellung unserer Summgeräusch-Erkennung auf der INTERSPEECH 2023
Ramin hat unsere Erkennung von Summgeräuschen mit Deep-Learning auf der prestigeträchtigen INTERSPEECH Konferenz in Dublin vorgestellt.
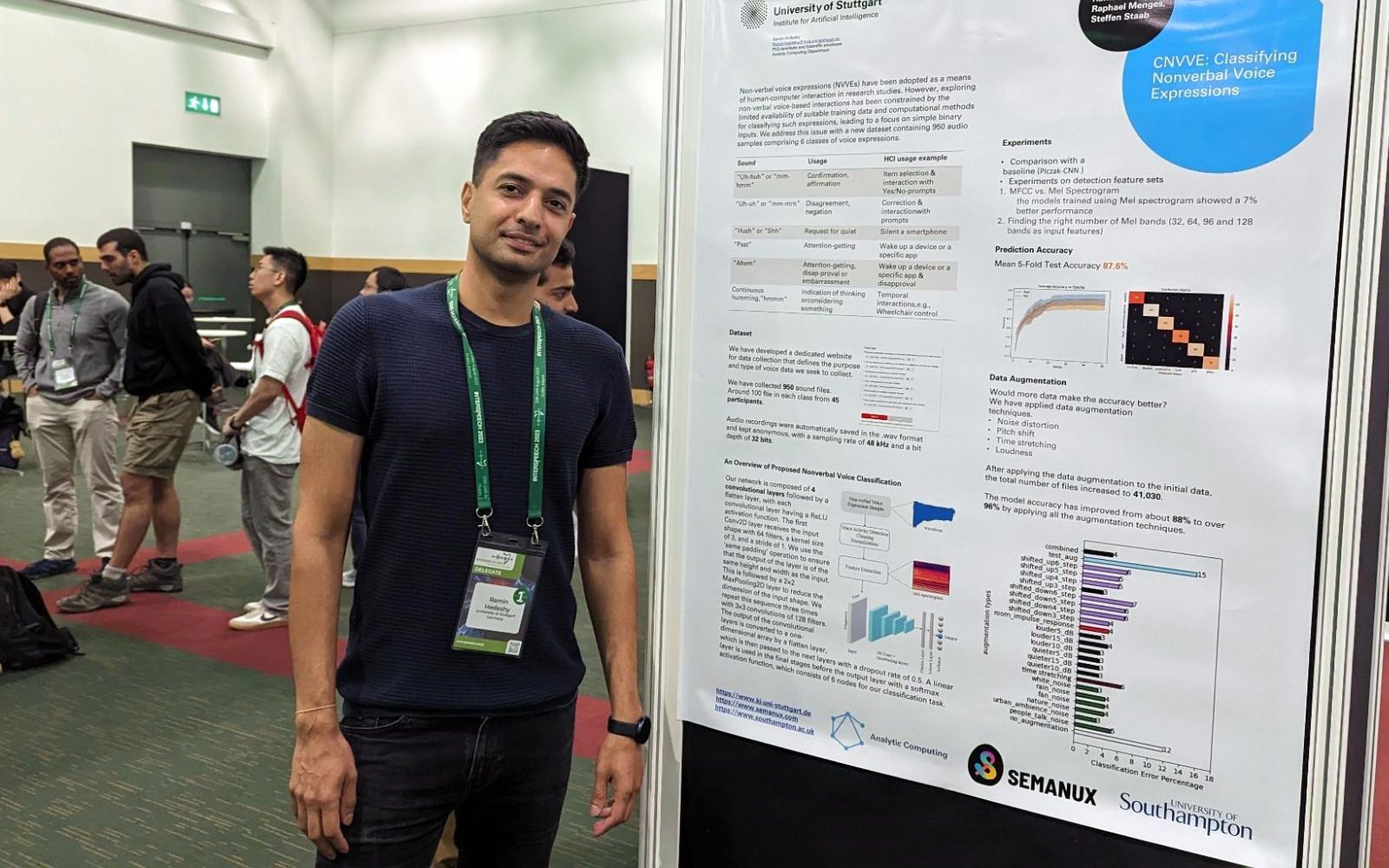
Unser Anspruch, bei Semanux hochinnovative Technologien zu entwickeln und damit den Zugang zur digitalen Welt für alle zu verbessern, ist ein großes Versprechen. Dass wir es damit nicht untertreiben, konnte Ramin in der vergangenen Woche mit der Vorstellung unserer Erkennung von Summgeräuschen auf der international geachteten Konferenz INTERSPEECH in Dublin, Irland, demonstrieren. Die INTERSPEECH ist die weltweit größte und umfassendste Konferenz über die Wissenschaft und Technologie der Verarbeitung gesprochener Sprache und wird von Apple und Google Research gesponsert.
Mit unserer Technologie kann ein Computer unterscheiden, welches Summgeräusch ein Mikrofon gerade gehört hat. Ist es ein zustimmendes „Uh-huh” oder ein ablehnendes „Uh-uh”? Unsere Technologie erkennt dabei Summgeräusche von sechs verschienen Arten mit einer Genauigkeit von 96,6%. Mit dieser Technologie lassen sich zuverlässig Aktionen am Computer durch Summgeräusche ausführen - vom Klicken über den Programmstart bis hin zur Eingabe von Texten.
Unser Beitrag zur INTERSPEECH wurde von der „International Speech Communication Association” publiziert und kann folgenderweise zitiert werden:
Hedeshy, R., Menges, R., Staab, S. (2023) CNVVE: Dataset and Benchmark for Classifying Non-verbal Voice. Proc. INTERSPEECH 2023, 1553-1557, doi: 10.21437/Interspeech.2023-201
Der Beitrag besteht aus unserem Datensatz aus Summgeräuschen von 950 Aufnahmen die wir mit 42 Teilnehmer*innen aufgezeichnet haben, Quellcode um den Datensatz zu verarbeiten und ein Deep-Learning-Modell für die Erkennung von Summgeräuschen zu erzeugen, und einem Forschungspapier, dass den Datensatz und das Modell im Detail erklärt und diskutiert. Mit dem offenen Datensatz und dem offenen Quellcode ermöglichen wir es allen Forschern auf der Welt, die Erkennung von Summgeräuschen zu verbessern.

